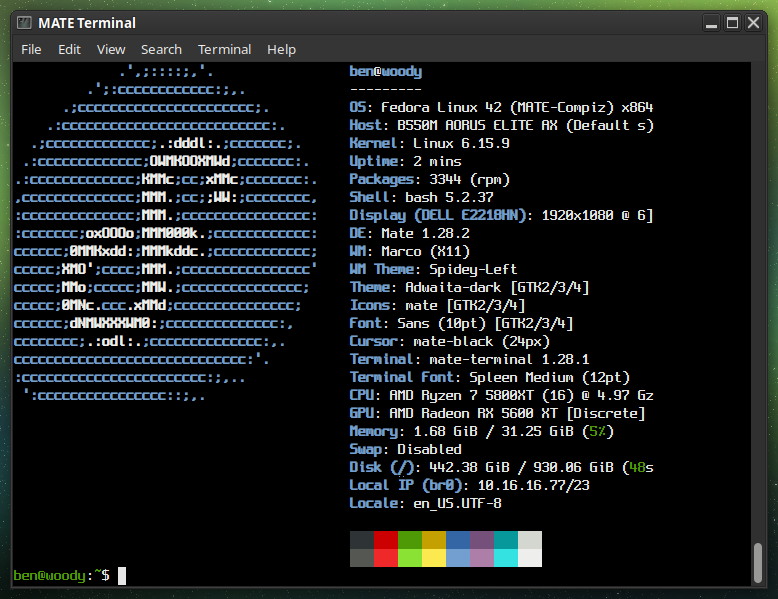
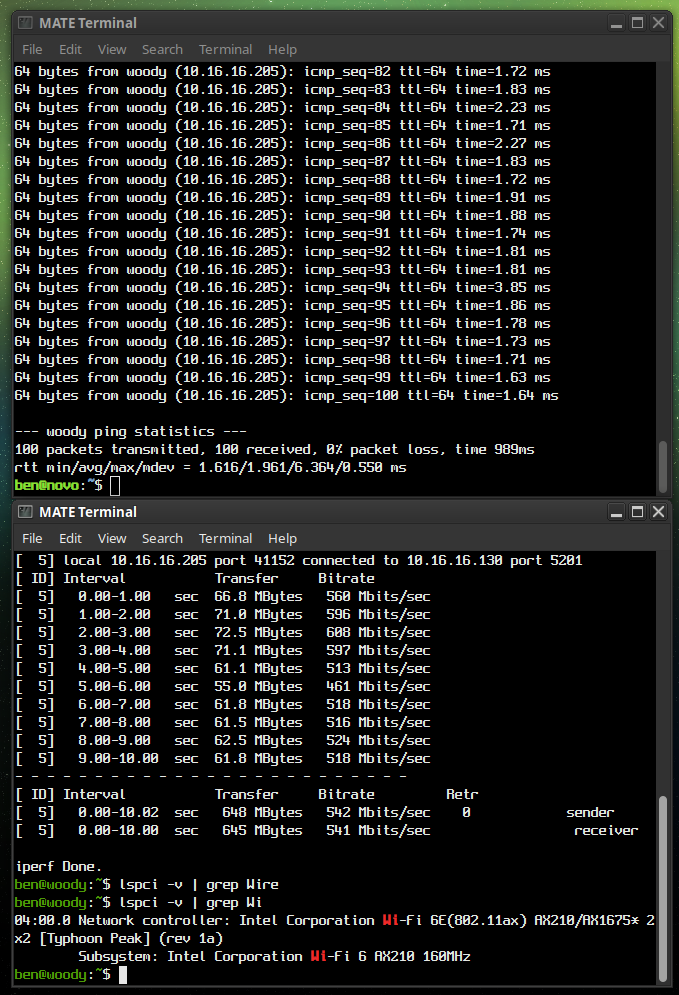
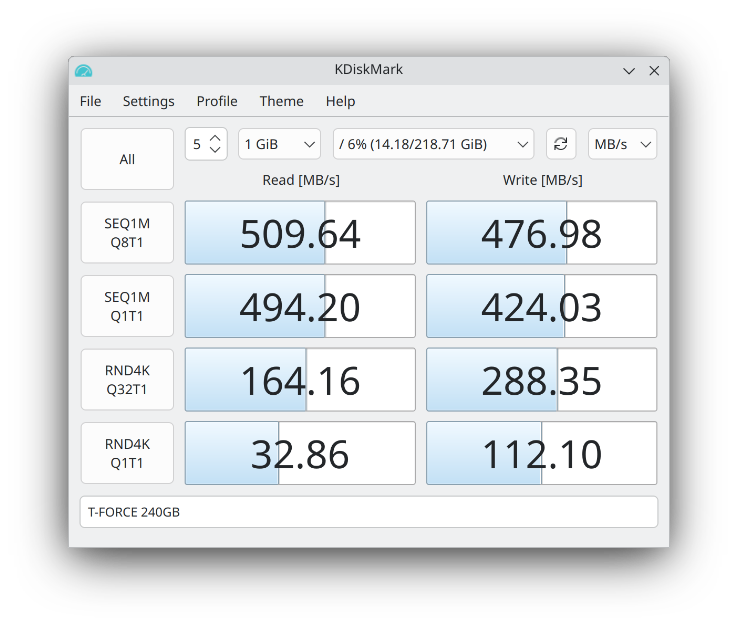
Preface: I’m a long-time GNU/Linux user, extensively familiar with systems like Debian and Fedora. I don’t mind getting my hands dirty, and I’ve used plenty of distributions that are generally believed to be less user-friendly than your average Ubuntu flavor — namely Alpine Linux, FreeBSD, and OpenBSD.
So, what is Arch Linux, and who is it for?
If I had to answer that myself and offer my own take, it would be this: Arch is a rolling-release distribution with the latest packages and a remarkably broad selection of software. You’ll have at your fingertips the very latest in Linux and free software — you’ll be on the bleeding edge.
Arch is also a build-it-yourself kind of distro, in the sense that you’ll need to choose and configure your own desktop environment, sound server, display server, and so on. It’s more popular than ever among Linux power users, and it’s easy to see why.
How does it compare to Debian Sid? Fedora Rawhide?
First, let’s clear up a common point of confusion: when people say “Sid,” they often mean Debian Testing. Testing is the middle ground between Unstable and Stable in the Debian ecosystem. Typically, it won’t have broken packages — though it can — but it may be missing them entirely at times.
Unstable, on the other hand, does hold buggy, broken, in-development software. Testing is for software that’s somewhat stable and functioning, but not yet officially “release-ready.”
Debian does a new “Stable” release (a major version, e.g., Bookworm) roughly every two years. When new packages are built, they first enter “Unstable,” and once they work well enough, they move to “Testing.” Leading up to a new release, a freeze occurs. During the freeze, new code and features are no longer accepted into Testing — only bug fixes are allowed. This model prioritizes stability, and it’s similar to how the Linux kernel is developed: features freeze at a certain point, so that the remaining effort is focused on polishing what’s already there.
For completeness: Fedora takes a similar approach, but it’s simpler in terms of branches. They have the latest official release (e.g., Fedora 41), and then there’s Rawhide, which is Fedora’s rolling-release/unstable branch.
Wait… I thought this was supposed to be about Arch Linux?!
I’m getting back to that.
So where does Arch fall into all this? Well, Debian Stable — Arch is not. And by that, I mean they’re completely different animals.
Sometimes, you want something that’s tried and true, something that just works. There’s nothing wrong with Debian’s release model — in fact, Debian is one of the most widely used Linux distributions on desktops, and it’s arguably even more dominant on servers.
Right now, for example (April 2025), Debian 12 Bookworm is almost two years old. That means that, for the most part, the software it includes is also about two years old. Some packages may be even older. This doesn’t mean the software is bad, but it’s technically “old.” Features don’t normally change during a stable release’s lifecycle — only security updates and critical bug fixes are provided.
In contrast, Arch gets you as close to the upstream as possible. Things should work, but they haven’t been battle-tested the same way. Debian Stable, on the other hand, continues to be supported even after it’s no longer the current release — with bug fixes and security updates maintained under its “Old Stable” status. These days, a single Debian release can easily be used for up to eight years or more.
When does Arch Linux make the most sense?
If you’ve got a brand-new, cutting-edge piece of hardware, Arch might be the most sensible choice. You’ll likely want the latest Linux kernel for full support — and yes, you can build a new kernel on any distro, but we’re not talking about that level of work here.
Because Arch combines a bleeding-edge model with a huge package repository, you can choose to run either the latest stable kernel or an LTS (Long-Term Support) kernel, depending on your preference. For context: when we say “stable” in terms of the Linux kernel, we don’t mean “stable” like Debian Stable — we just mean it’s a non-development, non-RC release.
If you have a high-DPI display, a high-end GPU, or you just want to test the latest in GNOME or KDE, Arch is a fantastic choice. As I mentioned earlier, you’ll be able to install much more recent builds of almost everything than what you’d find in something like Debian Stable.
Why not just use Debian Testing or Sid, then?
You can, and if you’re already comfortable with Debian, trying out Testing isn’t a bad idea. In fact, Testing can often be run day-to-day without major issues. But Sid (Unstable) is another story entirely — and if you try to mix packages from Stable, Testing, and Unstable, you’re very likely to run into messy dependency hell and package management headaches.
While Testing can function as a sort of rolling release, that’s not really its purpose. It exists primarily for development and staging of Debian’s next Stable version. Arch, on the other hand, is a rolling release — plain and simple. If a package is in the repository, it’s supposed to work. And if something breaks, you can usually roll it back, and a fix will likely come soon.
In conclusion…
Well — I haven’t come to one yet, and I can’t say there will be a definitive conclusion, per se.
As I write this, I’m on my second or third day of giving Arch a good, honest trial on my laptop. So far, I’m liking it quite a bit. I’ll no doubt have a follow-up at some point, but I think I’ve stated the majority of my opinions up above.
Stay tuned.